Integrated Data Analysis Pipelines for Large-Scale Data
Management, HPC, and Machine Learning
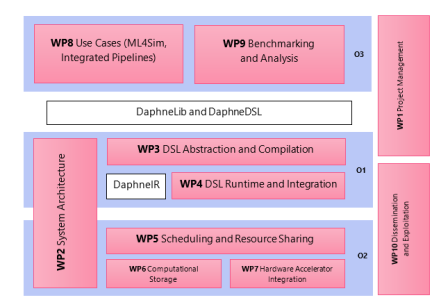
The DAPHNE project aims to define and build an open and extensible system infrastructure for integrated data analysis pipelines, including data management and processing, high-performance computing (HPC), and machine learning (ML) training and scoring. This vision stems from several key observations in this research field:
- Systems of these areas share many compilation and runtime techniques.
- There is a trend towards complex data analysis pipelines that combine these systems.
- The used, increasingly heterogeneous, hardware infrastructure converges as well.
- Yet, the programming paradigms, cluster resource management, as well as data formats and representations differ substantially.
A depiction of an example data pipeline shows the typical challenges researchers are confronted with while building and executing such pipelines:
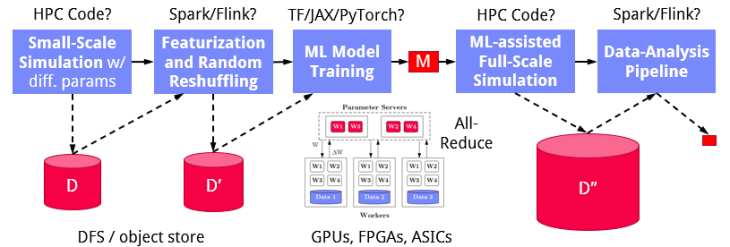
Therefore, this project aims – with a joint consortium of experts from the data management, ML systems, and HPC communities – at systematically investigating the necessary system infrastructure, language abstractions, compilation and runtime techniques, as well as systems and tools necessary to increase the productivity when building such data analysis pipelines, and eliminating unnecessary performance bottlenecks.